
Scaling Decentralized Training
Arceus is a marketplace platform that lets people rent out their computer's processing power to help train AI models. The platform connects students, researchers, and developers who need computing resources with people who have powerful computers sitting idle, creating an Uber-like network of shared computing power.
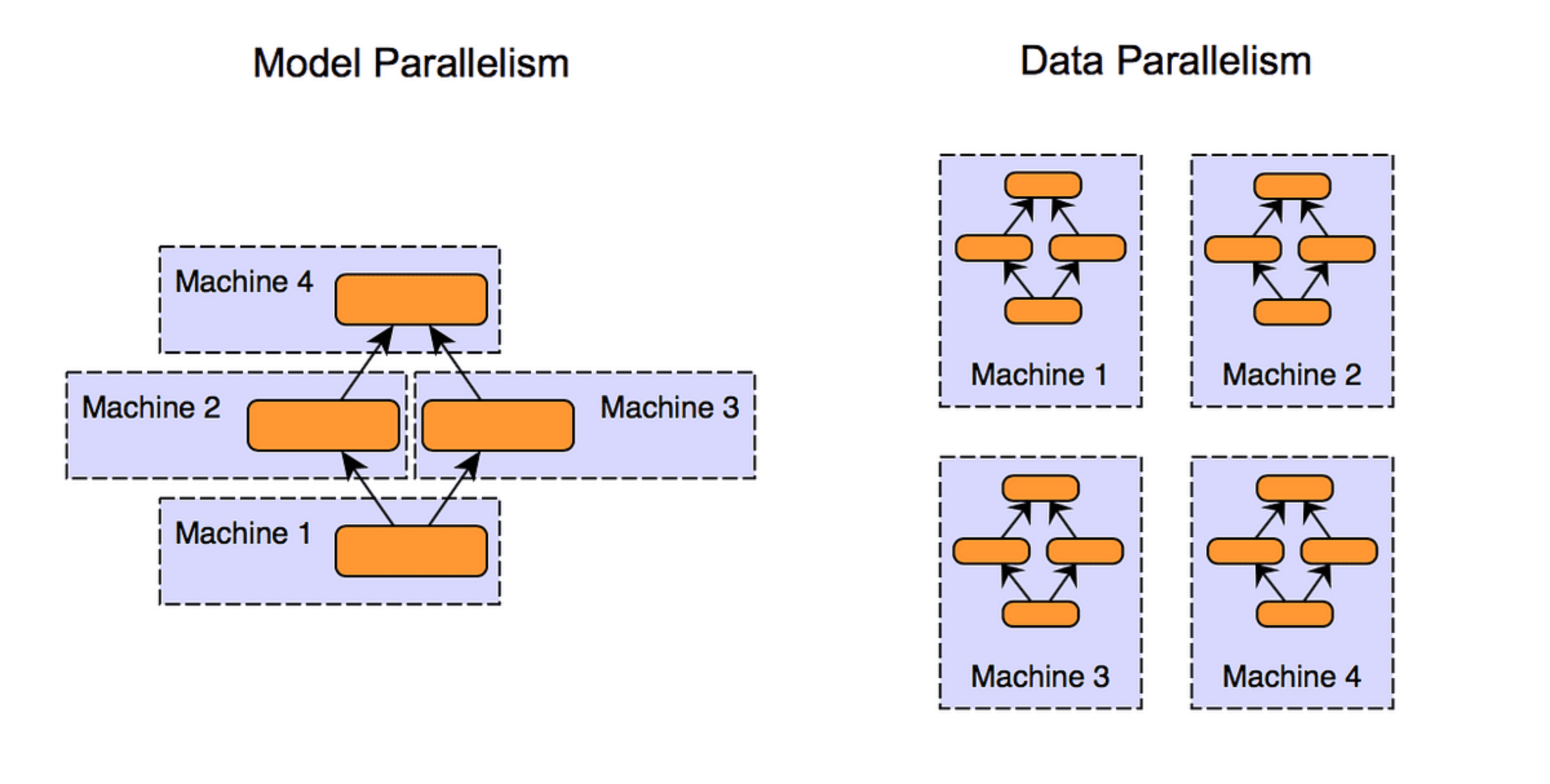
We take advantage of model parallelism to distribute model training across devices on the network. Layers, or fragments of them, are dynamically allocated to different devices, ensuring each device is only doing background tensor operations on demand. This makes AI model training more affordable and accessible since users don't need expensive enterprise hardware, while also letting device owners earn passive income by contributing their unused computing power.
Model Parallelism
Arceus uses model parallelism to distribute the training of large-scale AI models across a decentralized network of devices, turning idle compute resources into an affordable and scalable alternative to enterprise-grade hardware. By splitting a model's layers—or fragments of those layers—across multiple devices, we ensure that no single device needs to store or process the entire model. Instead, each device handles only the tensor computations for its assigned portion of the model. During the forward pass, activations (the outputs of a layer) are passed from one device to the next as the computation progresses sequentially. While data parallelism allows us to do parallel computation of gradients, the syncing process is computationally expensive and requires each device to store the entire model, not optimal for a marketplace for background GPU usage on consumer hardware.
During the backward pass, gradients are calculated locally and sent back in reverse order to update the corresponding parameters. This design requires efficient communication between devices—we chose gRPC, which serializes activations and gradients into compact binary format for low-latency transfers over the network, minimizing bottlenecks introduced by inter-device communication.
We focused on Macbooks for our experiment to use PyTorch's MPS backend, which accelerates tensor operations by using the shared GPU and CPU memory space. This eliminates the need for costly memory copies between components, a common issue on traditional heterogeneous systems. When layers or tensor fragments are allocated to MPS-enabled devices, the unified memory allows seamless read/write operations during forward and backward passes. Additionally, MPS's low-level optimizations for matrix multiplications and element-wise tensor operations provide near-GPU performance even for devices without discrete GPUs.
Tensor Parallelism
For transformer-based models, Arceus implements tensor parallelism to distribute memory-intensive operations like the attention mechanism. Transformers require large matrix multiplications for computing query, key, and value projections across multiple attention heads, which can quickly exceed the memory capacity of a single device. In Arceus, these weight matrices are divided row-wise or column-wise and split across devices. For instance, in an attention layer with eight heads, four heads might be computed on one device, while the remaining four are processed elsewhere.
Each device handles its local computations, such as matrix multiplications and softmax operations, before sending its partial results back for aggregation into the final tensor. During the backward pass, the same process occurs in reverse: gradients for each partitioned weight matrix are calculated locally and combined to produce the global gradients required for parameter updates. This splitting ensures that devices act as "matrix multiplication machines" and do not store entire models.
Pipeline Parallelism
To maximize throughput, Arceus also integrates pipeline parallelism by dividing the model into sequential stages and processing input data as a stream of micro-batches. Each stage of the model is assigned to a different device, and micro-batches flow through the pipeline in overlapping fashion. For example, while Device 1 processes the forward pass for Micro-batch 1, Device 2 begins working on the forward pass for Micro-batch 2, and so forth. During the backward pass, gradients are similarly propagated back through the pipeline in reverse order, overlapping computations to minimize device idle time.
Why gRPC?
We chose gRPC as our protocol for its highly efficient binary serialization, minimizing network overhead when transferring tensors between devices. The bidirectional streaming support is essential for our pipeline parallelism, allowing devices to maintain long-lived connections and stream micro-batches without connection overhead. Built on HTTP/2, gRPC enables multiplexing and header compression to further reduce latency.
Results
We built Arceus to handle deep neural networks and the transformer architecture across multiple devices on a local network and are setting up a server to handle requests across Wifi. In our initial tests, we trained the MNIST dataset and some large neural networks across devices on our network at the University of Waterloo. As the project progressed, we trained a simple 5M parameter language model based on the transformer architecture using our framework. This training took approximately 20 minutes across 3 M1-series Macbooks. We demoed our work to investors at a16z, Sequoia & Thrive, engineers at OpenAI, Anthropic, Tesla & Apple and C-suite executives at Ramp and Ollama.

Over the next several months, we hope to make our process more efficient and make decentralized training extremely simple. We greatly admire the work by Omkaar, Exo and Prime Intellect. We hope to turn Waterloo into a supercomputer.
For a comprehensive design case study, visit Ishaan Dey's Website.